
(1/3) Daten speichern und analysieren auf dem Pi mit InfluxDB und Grafana
Dies ist Teil 1 der 3-teiligen Serie
- Teil 1: InfluxDB
- Teil 2: Grafana
- Teil 3: Daten auswerten und analysieren
Sensoren für Temperatur, Luftfeuchtigkeit, Luftqualität, Feuchtigkeit der Pflanzenerde, Server Monitoring, Körpergewicht, Wetter, Trocker- und Waschmaschinen-Aktivität, Stromverbrauch … und viele weitere IoT und IT Anwendungen haben folgendes gemeinsam:
- Sie produzieren Daten am laufenden Band. Manche im Sekundentakt, andere nur alle paar Tagen.
- Die gesammelten sollen ausgewertet und sinnvoll repräsentiert werden. Dazu gehört das Verglichen und veranschaulichen von Entwicklungen über die Zeit.
- Die Daten sollen über einen langen Zeitraum gespeichert werden, jedoch (je nach Anwendung) irgendwann auch wieder „verfallen“.
Dies ist kein neues Problem. Die Messwerte und Ereignisse werden als Zeitserie in sogenannten time series database (TSDB), also Zeitserien-Datenbanken gespeichert.
Die bekanntesten OpenSource Datenbank-Systeme dieser Gattung sind:
- RRDtool
- Graphite (Whisper)
- Prometheus
- InfluxDB (mit Grafana)
Backend: InfluxDB
InfluxDB ist OpenSource, wird aktiv weiterentwickelt, es gibt eine große Community und eine große Auswahl an Software mit InfluxDB Integration.
Nicht zu vergessen sind auch die Systemanforderungen: Wir wollen das ganze auf einem Raspberry Pi betreiben.
InfluxDB installieren
Ich gehe hier davon aus, dass der Raspberry Pi schon mit dem Linux System der DietPi Distribution vorinstalliert wurde. Ist dem nicht der Fall, gibt es hier eine kurze Anleitung.
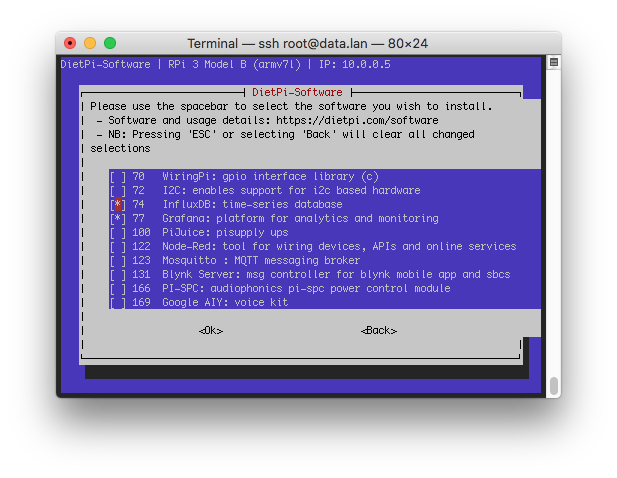
dietpi-software > Software Optimised > InfluxDBInfluxDB kann, wie oben zu sehen ist, über eine Text-Oberfläche installiert werden, oder einfach über folgenden Befehl:
dietpi-software install 74InfluxDB sollte nun installiert und minimal vorkonfiguriert sein. Der Dienst wird automatisch beim booten gestartet.
Wie in DietPi üblich, werden auch hier die Daten im einem Verzeichnis gesammelt, was das erstellen von Sicherungskopien erheblich vereinfacht: /mnt/dietpi_userdata/influxdb
InfluxDB konfigurieren
In den nächste Schritten sichern wir InfluxDB ab, legen eine Testdatenbank an, machen den Dienst über HTTP für unser Frontend (Grafana) erreichbar und optimieren die Leistung ein wenig.
1. Administrator mit allen Rechen anlegen
influxCREATE USER admin WITH PASSWORD 'GeHeiM' WITH ALL PRIVILEGES
exit2. Wir erstellen eine Datenbank „test_data“
influx -username admin -password GeHeiMCREATE DATABASE test_data
exit3. Wir legen einen Benutzer zum testen an
Wir wollen ja nich unsere Admin Zugangsdaten überall verteilen. Je nachdem welche Anwendung man konfiguriert, sind die Zugangsdaten in der Konfiguration für viele Systemnutzer einsehbar.
Dich individuelle Zugriffsrechte der verschiedenen Benutzer, kann man auch verhindern, dass man durch versehentliche Fehlkonfiguration, alle Daten löscht oder überschreibt.
Es empfiehlt sich, für jede Anwendung (Node-RED, Telegraf, Grafana, …) einen eigenen Benutzer mit passenden Zugriffsrechten anzulegen, um potenziellen Schaden zu begrenzen.
Zitat: Jeder erfahrene Administrator
influx -username admin -password GeHeiMCREATE DATABASE test_data
CREATE USER meine_anwendung WITH PASSWORD 'AuChGeHeIm'
GRANT ALL ON test_data TO meine_anwendung
exit4. Zugriff über HTTP aktivieren
Nach der Installation ist der Zugriff über HTTP üblicherweise deaktiviert. Um diesen zu aktivieren, müssen wir die InfluxDB Konfiguration in /etc/influxdb/influxdb.conf anpassen und enabled und auth-enabled auf true setzen:
nano /etc/influxdb/influxdb.conf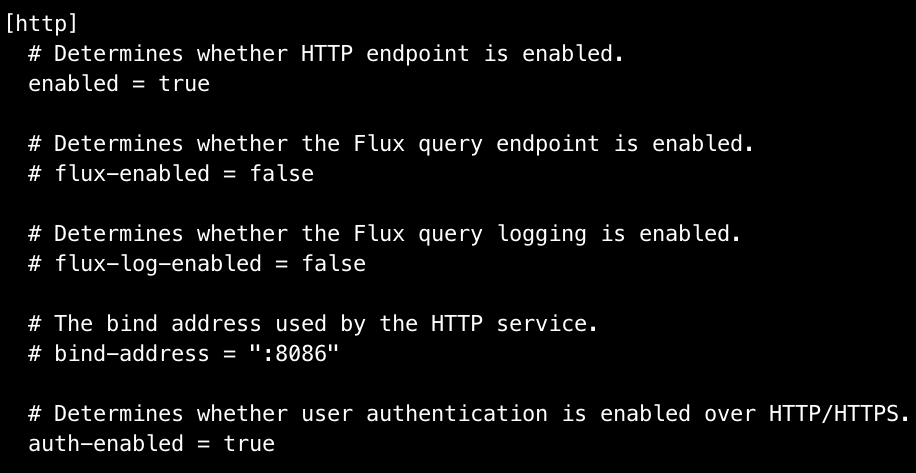
Nach dem ändern der Konfiguration, musst den Dienst mit service influxdb restart neu starten, damit die Änderungen wirksam werden.
Mit service influxdb status kannst du überprüfen, ob noch alles funktioniert.
5. InfluxDB für den Raspberry Pi optimieren
Wenn man eine Raspberry Pi (oder andere SBC) betreibt, sollte man ein paar Dinge beachten:
- Der Hauptspeicher ist begrenzt (meist 1GB)
- Die Prozessorleistung ist begrenzt
- Es werden SD oder eMMC Speichermedien verwendet, die eine begrenzte Lebensdauer haben. Unnötiges schreiben in Dateien sollte daher vermieden werden.
Die hier von uns verwendete DietPi Distribution hat uns das meiste schon abgenommen.
- Es wird nur das nötigste an Diensten gestartet
- Das loggen ist deaktiviert, bzw. wird im Hauptspeicher gehalten
InfluxDB sammelt Metriken und andere Daten über sich selbst und speichert diese in einer internen Datenbank. Das ist für den Normalanwender nicht nötig.
Wir deaktivieren das sammeln der internen Metriken und sparen uns damit unnötige Datei-Speicherzugriffe und reduzieren messbar die Dauerlast auf dem Prozessor.
Hierfür muss in der Datei /etc/influxdb/influxdb.conf im Abschnitt [Monitor] der Eintrag store-enabled = false einkommentiert und auf false gesetzt sein:
nano /etc/influxdb/influxdb.conf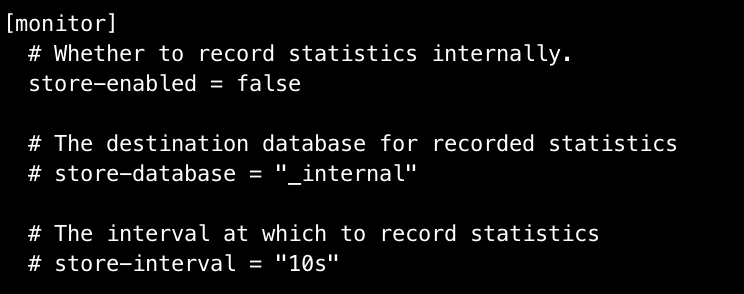
Dann nur noch InfluxDB mit service influxdb restart neu starten, damit die Änderungen wirksam werden.
Das war Teil 1 der Serie “Daten speichern und analysieren auf dem Pi mit InfluxDB und Grafana”.
- Teil 1: InfluxDB
- Teil 2: Grafana
- Teil 3: Daten auswerten und analysieren
Hallo, gibt es noch Teil 2 und 3?
Hallo Stefan,
Durch unseren Umzug ins Eigenheim, blieb hier auf OnkelJordi vieles “auf der Strecke”.
Teil 2 und 3 sind inhaltlich fertig, aber müssen nur noch etwas poliert werden.
Ich werde versuchen, diese beiden Posts diese Woche abzuschießen 🙂
+1
Ich würde mich auch über einen “pre-release” einer beta version der weiteren beiden Kapitel freuen 🙂
Etwaige Probleme würde ich dir zurückmelden.
Ich kann Tante Hertha nur recht geben: Es muss gar nicht schön poliert sein, Hauptsache wir kriegen das auch an’s laufen …
Hi, auch ich erwarte noch sehnlichst Teil 2 und 3!
Ich finde, das Eigenheim kann auch mal warten 😉